
中国全科医学 ›› 2022, Vol. 25 ›› Issue (34): 4267-4277.DOI: 10.12114/j.issn.1007-9572.2022.0358
所属专题: 内分泌代谢性疾病最新文章合辑
贺婷, 袁丽*( ), 杨小玲, 叶子溦, 李饶, 古艳
), 杨小玲, 叶子溦, 李饶, 古艳
收稿日期:2022-05-16
修回日期:2022-09-11
出版日期:2022-12-05
发布日期:2022-09-29
通讯作者:
袁丽
基金资助:
HE Ting, YUAN Li*(), YANG Xiaoling, YE Ziwei, LI Rao, GU Yan
Received:2022-05-16
Revised:2022-09-11
Published:2022-12-05
Online:2022-09-29
Contact:
YUAN Li
About author:摘要: 背景 2型糖尿病(T2DM)的患病率不断上升。2021年成年糖尿病患者人数最多的10个国家中,有6个是亚洲国家。可靠的T2DM发病风险预测模型能够识别有患T2DM风险的个体,并可为开展针对性的预防干预工作提供决策依据。 目的 系统分析、评价亚洲T2DM发病风险预测模型,以期为T2DM的防治提供参考。 方法 于2021年4月,计算机检索PubMed、EmBase、the Cochrane Library获取有关亚洲T2DM发病风险预测模型的研究,检索时限均为建库至2021-04-01。由2名研究者独立筛选文献、提取资料后,应用预测模型研究偏倚风险评估工具(PROBAST)评价纳入文献的偏倚风险和适用性。采用描述性分析法对模型的基本特征及纳入研究的偏倚风险与适用性评价结果进行总结、分析。 结果 共纳入31项亚洲T2DM发病风险预测模型研究,其中17项为前瞻性队列研究,14项为回顾性队列研究。纳入研究多采用Cox回归、Logistic回归构建模型;5项研究仅对模型进行了外部验证,22项研究仅对模型进行了内部验证,4项研究采用内部验证与外部验证相结合的方法对模型进行了验证。模型的受试者工作特征曲线下面积为0.62~0.92,包含预测因子数量为3~24个。纳入研究均存在较高的偏倚风险,主要原因为对连续变量的处理不合理、对缺失数据的处理不合理、忽略了模型的过度拟合问题等。 结论 纳入的模型具有良好的预测效能,可帮助医务人员早期识别T2DM发病高风险人群。未来,应对数据建模及统计分析方法进行改进,开发性能优良、偏倚风险低的预测模型,注重对模型进行外部验证和重新校准。
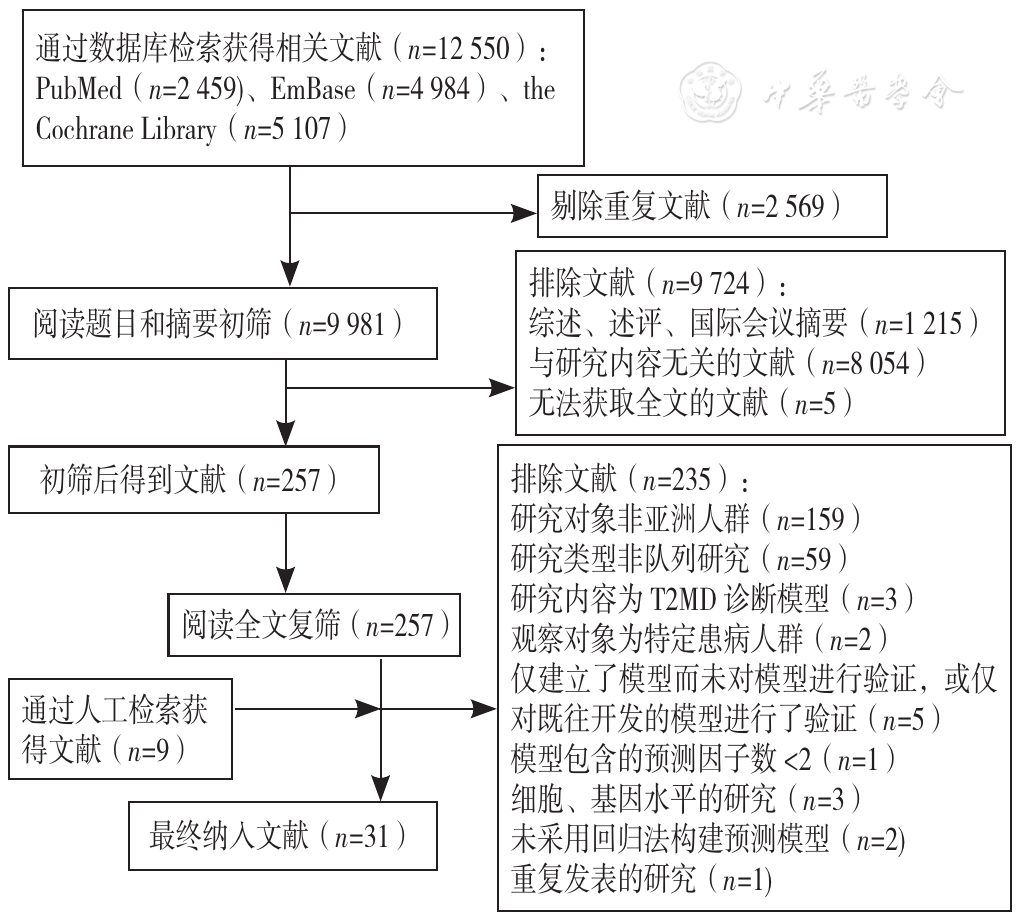
图1 文献筛选流程注:T2DM=2型糖尿病
Figure 1 Literature screening flowchart
| 第一作者 | 发表年份(年) | 国家(地区) | 研究类型 | 研究对象年龄(岁) | 样本来源 | 样本量(不包含缺失数据) | 发生结局事件的患者数(例) | 随访时长(年) | 观察终点a |
|---|---|---|---|---|---|---|---|---|---|
| AEKPLAKORN等[ | 2006 | 泰国 | 前瞻性队列研究 | 35~55 | 泰国发电局 | D:2 677 V:2 420 | D:361 V:125 | 12 | ①③④⑤ |
| CHIEN等[ | 2009 | 中国 | 前瞻性队列研究 | ≥35 | 台北县金山乡(排除有心血管疾病或癌症病史者) | 2 960 | 548 | 10 | ①④ |
| GAO等[ | 2009 | 毛里求斯 | 前瞻性队列研究 | 20~65 | 居住在毛里求斯的10个人口群(均为印度人) | 3 094 | 511 | 11 | ③ |
| SUN等[ | 2009 | 中国 | 回顾性队列研究 | 35~74 | 台北、桃园、台中和高雄县4家健康体检中心 | 73 961 | 3 612 | 3.15 | ①④ |
| CHUANG等[ | 2011 | 中国 | 回顾性队列研究 | ≥35 | 台北、桃园、台中和高雄县4家健康体检中心 | 24 899 | 1 261 | 5.61±3.33 | ①④ |
| BOZORGMANESH等[ | 2011 | 伊朗 | 前瞻性队列研究 | ≥20 | 德黑兰血脂和血糖研究 | 3 242 | 231 | 6 | ①③④ |
| LIU等[ | 2011 | 中国 | 前瞻性队列研究 | 40~90 | 北京市某医院筛查中心 | 1 851 | 352 | 10 | ①③④⑤ |
| ONAT等[ | 2011 | 土耳其 | 前瞻性队列研究 | ≥28 | 土耳其成人风险因素研究 | 2 261 | 212 | 7.6 | ①③④ |
| DOI等[ | 2012 | 日本 | 前瞻性队列研究 | 40~79 | 福冈县久山町 | D:1 935 V:1 147 | D:286 V:89 | 14 | ①③④ |
| HEIANZA等[ | 2012 | 日本 | 前瞻性队列研究 | 40~75 | 虎之门医院附属健康管理中心 | D:7 654 V:1 437 | D:289 V:57 | 5 | ①②⑤ |
| LIM等[ | 2012 | 韩国 | 回顾性队列研究 | 40~69 | 韩国基因组和流行病学研究数据 | 1 912 | 924 | 4 | ①②③④ |
| YE等[ | 2014 | 中国 | 前瞻性队列研究 | 50~70 | 北京市和上海市的城乡社区 | 6 342 | 436 | 6 | ①②④⑤ |
| XU等[ | 2014 | 中国 | 前瞻性队列研究 | ≥50 | 广州尊老康乐协会 | 16 043 | 1 063 | 4.1 | ①④⑤ |
| NANRI等[ | 2015 | 日本 | 回顾性队列研究 | ≥30 | 12家公司 | D:37 416 V:12 466 | D:1 122 V:565 | 5 | ①②④⑥ |
| WANG等[ | 2016 | 中国 | 回顾性队列研究 | ≥18 | 唐山市开滦社区 | D:49 325 V:24 662 | 4 726 2 327 | 5.35±1.59 | ①④⑤ |
| LIU等[ | 2016 | 中国 | 回顾性队列研究 | 55~96 | 北京市社区 | 1 857 | 144 | 20 | ①④⑤ |
| MIYAKOSHI等[ | 2016 | 日本 | 回顾性队列研究 | — | 相泽医院健康中心 | 4 159 | 279 | 4.9 | ①②③ |
| ZHANG等[ | 2016 | 中国 | 前瞻性队列研究 | ≥18 | 农村 | 14 134 | 729 | 6 | ①④ |
| CHEN等[ | 2017 | 中国 | 回顾性队列研究 | ≥18 | 浙江省德清县农村 | D:28 251 V:3 043 | 387 191 | 4.2 | ①④⑤ |
| ZHANG等[ | 2017 | 中国 | 前瞻性队列研究 | ≥18 | 河南省洛阳市农村 | 15 768 | 702 | 6 | ①④⑤ |
| WEN等[ | 2017 | 中国 | 回顾性队列研究 | ≥30 | 河北省邯郸市永年区的社区 | 4 132 | 218 | 6 | ①③④⑤ |
| YATSUYA等[ | 2018 | 日本 | 前瞻性队列研究 | 35~64 | 爱知县政府 | 3 540 | 342 | 12.2 | ①②④⑤ |
| HA等[ | 2018 | 韩国 | 回顾性队列研究 | — | 韩国国民健康保险数据库、韩国基因组和流行病学研究数据 | D:359 349 V:6 660 | D:37 678 V:1 040 | 10.8 | ①②③⑤ |
| HAN等[ | 2018 | 中国 | 回顾性队列研究 | — | 东风汽车集团有限公司 | 17 690 | 1 390 | 5 | ①④⑤ |
| HU等[ | 2018 | 日本 | 回顾性队列研究 | 30~59 | 12家公司(排除癌症、心血管疾病患者) | 46 198 | 3 385 | 8 | ①②④⑥ |
| WANG等[ | 2019 | 中国 | 前瞻性队列研究 | — | 于武汉联合医院接受年度健康体检的居民(排除癌症、心血管疾病和卒中患者) | D:5 557 V:1 870 | D:595 V:206 | 3 | ①③④ |
| GUNTHER等[ | 2020 | 新加坡 | 前瞻性队列研究 | — | 新加坡前瞻性研究计划 | 3 313 | 314 | 8.4 | ①②⑤ |
| SHAO等[ | 2020 | 中国 | 回顾性队列研究 | 20~80 | 中国健康与营养调查项目(排除妊娠者和心血管疾病患者) | 6 023 | 349 | 10 | ①②③⑥ |
| ASGARI等[ | 2021 | 伊朗 | 前瞻性队列研究 | ≥20 | 德黑兰城区人口 | D:5 291 V:3 147 | 214 | 12 | ①②④ |
| OH等[ | 2021 | 韩国 | 前瞻性队列研究 | 40~69 | 韩国基因组和流行病学研究数据 | 5 673 | 1 291 | 10 | ①②③ |
| RHEE等[ | 2021 | 韩国 | 回顾性队列研究 | — | 韩国国民健康保险数据库 | 335 302 | 29 173 | 10.4 | ① |
表1 纳入的亚洲T2DM发病风险预测模型研究的基本信息
Table 1 Basic characteristics of included studies on risk prediction models for T2DM in Asian adults
| 第一作者 | 发表年份(年) | 国家(地区) | 研究类型 | 研究对象年龄(岁) | 样本来源 | 样本量(不包含缺失数据) | 发生结局事件的患者数(例) | 随访时长(年) | 观察终点a |
|---|---|---|---|---|---|---|---|---|---|
| AEKPLAKORN等[ | 2006 | 泰国 | 前瞻性队列研究 | 35~55 | 泰国发电局 | D:2 677 V:2 420 | D:361 V:125 | 12 | ①③④⑤ |
| CHIEN等[ | 2009 | 中国 | 前瞻性队列研究 | ≥35 | 台北县金山乡(排除有心血管疾病或癌症病史者) | 2 960 | 548 | 10 | ①④ |
| GAO等[ | 2009 | 毛里求斯 | 前瞻性队列研究 | 20~65 | 居住在毛里求斯的10个人口群(均为印度人) | 3 094 | 511 | 11 | ③ |
| SUN等[ | 2009 | 中国 | 回顾性队列研究 | 35~74 | 台北、桃园、台中和高雄县4家健康体检中心 | 73 961 | 3 612 | 3.15 | ①④ |
| CHUANG等[ | 2011 | 中国 | 回顾性队列研究 | ≥35 | 台北、桃园、台中和高雄县4家健康体检中心 | 24 899 | 1 261 | 5.61±3.33 | ①④ |
| BOZORGMANESH等[ | 2011 | 伊朗 | 前瞻性队列研究 | ≥20 | 德黑兰血脂和血糖研究 | 3 242 | 231 | 6 | ①③④ |
| LIU等[ | 2011 | 中国 | 前瞻性队列研究 | 40~90 | 北京市某医院筛查中心 | 1 851 | 352 | 10 | ①③④⑤ |
| ONAT等[ | 2011 | 土耳其 | 前瞻性队列研究 | ≥28 | 土耳其成人风险因素研究 | 2 261 | 212 | 7.6 | ①③④ |
| DOI等[ | 2012 | 日本 | 前瞻性队列研究 | 40~79 | 福冈县久山町 | D:1 935 V:1 147 | D:286 V:89 | 14 | ①③④ |
| HEIANZA等[ | 2012 | 日本 | 前瞻性队列研究 | 40~75 | 虎之门医院附属健康管理中心 | D:7 654 V:1 437 | D:289 V:57 | 5 | ①②⑤ |
| LIM等[ | 2012 | 韩国 | 回顾性队列研究 | 40~69 | 韩国基因组和流行病学研究数据 | 1 912 | 924 | 4 | ①②③④ |
| YE等[ | 2014 | 中国 | 前瞻性队列研究 | 50~70 | 北京市和上海市的城乡社区 | 6 342 | 436 | 6 | ①②④⑤ |
| XU等[ | 2014 | 中国 | 前瞻性队列研究 | ≥50 | 广州尊老康乐协会 | 16 043 | 1 063 | 4.1 | ①④⑤ |
| NANRI等[ | 2015 | 日本 | 回顾性队列研究 | ≥30 | 12家公司 | D:37 416 V:12 466 | D:1 122 V:565 | 5 | ①②④⑥ |
| WANG等[ | 2016 | 中国 | 回顾性队列研究 | ≥18 | 唐山市开滦社区 | D:49 325 V:24 662 | 4 726 2 327 | 5.35±1.59 | ①④⑤ |
| LIU等[ | 2016 | 中国 | 回顾性队列研究 | 55~96 | 北京市社区 | 1 857 | 144 | 20 | ①④⑤ |
| MIYAKOSHI等[ | 2016 | 日本 | 回顾性队列研究 | — | 相泽医院健康中心 | 4 159 | 279 | 4.9 | ①②③ |
| ZHANG等[ | 2016 | 中国 | 前瞻性队列研究 | ≥18 | 农村 | 14 134 | 729 | 6 | ①④ |
| CHEN等[ | 2017 | 中国 | 回顾性队列研究 | ≥18 | 浙江省德清县农村 | D:28 251 V:3 043 | 387 191 | 4.2 | ①④⑤ |
| ZHANG等[ | 2017 | 中国 | 前瞻性队列研究 | ≥18 | 河南省洛阳市农村 | 15 768 | 702 | 6 | ①④⑤ |
| WEN等[ | 2017 | 中国 | 回顾性队列研究 | ≥30 | 河北省邯郸市永年区的社区 | 4 132 | 218 | 6 | ①③④⑤ |
| YATSUYA等[ | 2018 | 日本 | 前瞻性队列研究 | 35~64 | 爱知县政府 | 3 540 | 342 | 12.2 | ①②④⑤ |
| HA等[ | 2018 | 韩国 | 回顾性队列研究 | — | 韩国国民健康保险数据库、韩国基因组和流行病学研究数据 | D:359 349 V:6 660 | D:37 678 V:1 040 | 10.8 | ①②③⑤ |
| HAN等[ | 2018 | 中国 | 回顾性队列研究 | — | 东风汽车集团有限公司 | 17 690 | 1 390 | 5 | ①④⑤ |
| HU等[ | 2018 | 日本 | 回顾性队列研究 | 30~59 | 12家公司(排除癌症、心血管疾病患者) | 46 198 | 3 385 | 8 | ①②④⑥ |
| WANG等[ | 2019 | 中国 | 前瞻性队列研究 | — | 于武汉联合医院接受年度健康体检的居民(排除癌症、心血管疾病和卒中患者) | D:5 557 V:1 870 | D:595 V:206 | 3 | ①③④ |
| GUNTHER等[ | 2020 | 新加坡 | 前瞻性队列研究 | — | 新加坡前瞻性研究计划 | 3 313 | 314 | 8.4 | ①②⑤ |
| SHAO等[ | 2020 | 中国 | 回顾性队列研究 | 20~80 | 中国健康与营养调查项目(排除妊娠者和心血管疾病患者) | 6 023 | 349 | 10 | ①②③⑥ |
| ASGARI等[ | 2021 | 伊朗 | 前瞻性队列研究 | ≥20 | 德黑兰城区人口 | D:5 291 V:3 147 | 214 | 12 | ①②④ |
| OH等[ | 2021 | 韩国 | 前瞻性队列研究 | 40~69 | 韩国基因组和流行病学研究数据 | 5 673 | 1 291 | 10 | ①②③ |
| RHEE等[ | 2021 | 韩国 | 回顾性队列研究 | — | 韩国国民健康保险数据库 | 335 302 | 29 173 | 10.4 | ① |
| 第一作者 | 连续变量处理方法 | 缺失数据 | 建模方法 | 变量选择方法 | 验模方法 | AUC(95%CI) | 拟合优度 | 过度拟合情况 | |
|---|---|---|---|---|---|---|---|---|---|
| 数量 | 处理方法 | ||||||||
| AEKPLAKORN等[ | 转化为分类变量 | D:587 V:459 | 完整个案分析 | Logistic回归 | 单因素分析、多因素分析 | 外部验证 | 模型1:0.74(0.71,0.78),0.75(0.71,0.80)。模型2:0.76(0.72,0.79)。模型3:0.78(0.75,0.81)。模型4:0.79(0.75,0.82)。模型5:0.79(0.76,0.82) | H-L拟合优度检验 | — |
| CHIEN等[ | 转化为分类变量 | — | 完整个案分析 | Cox回归 | 向前逐步选择法 | 内部验证 | 模型1:0.70(0.68,0.73)。模型2:0.65(0.62,0.67) | H-L拟合优度检验 | 交叉验证、自举法 |
| GAO等[ | 转化为分类变量 | — | 完整个案分析 | Cox回归 | — | 内部验证a | 模型1:男,0.62(0.56,0.68);女,0.64(0.59,0.69)。模型2:男,0.70(0.64,0.75);女,0.71(0.66,0.76)。模型3:男,0.71(0.66,0.77);女,0.71(0.66,0.76) | — | — |
| SUN等[ | 转化为分类变量 | — | — | Cox回归 | 逐步选择法 | 内部验证a | 模型1:0.751(0.730,0.773)。模型2:0.848(0.828,0.867)。模型3:0.853(0.834,0.872)。模型4:0.838(0.818,0.858)。模型5:0.843(0.824,0.863) | H-L拟合优度检验 | — |
| CHUANG等[ | 转化为分类变量 | — | — | Cox回归 | 逐步选择法 | 内部验证a | 模型1:0.71(0.70,0.73)。模型2:0.75(0.73,0.78)。模型3:0.72(0.71,0.74)。模型4:0.76(0.73,0.79)。模型5:0.82(0.81,0.83)。模型6:0.84(0.81,0.86) | — | — |
| BOZORGMANESH等[ | 转化为分类变量 | 1 776 | 完整个案分析 | Logistic回归 | 向前逐步选择法 | 内部验证 | 模型1:0.75(0.72,0.78)。模型2:0.85(0.82,0.87)。模型3:0.85(0.82,0.87) | H-L拟合优度检验 | 自举法 |
| LIU等[ | 转化为分类变量 | — | — | Logistic回归 | 单因素分析、多因素分析 | 外部验证 | 模型1:0.68(0.65,0.72)。模型2:0.71(0.68,0.75)。模型3:0.72(0.69,0.76) | — | — |
| ONAT等[ | 转化为分类变量 | — | — | Cox回归 | 向后逐步选择法 | 内部验证a | 男:0.78(0.74,0.83)。女:0.77(0.73,0.82) | — | — |
| DOI等[ | 转化为分类变量 | D:194 V:144 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 外部验证 | 模型1:0.70(0.67,0.73),0.69(0.63,0.75)。模型2:0.78(0.74,0.80),0.78(0.73,0.83) | H-L拟合优度检验 | — |
| HEIANZA等[ | 部分转化为分类变量 | D:137 V:15 | 完整个案分析 | Logistic回归 | 向前逐步选择法 | 外部验证 | 模型1:0.71(0.68,0.74),0.73(0.67,0.78)。模型2:0.84(0.82,0.86),0.87(0.83,0.90)。模型3:0.84(0.82,0.86),0.88(0.84,0.92)。模型4:0.89(0.87,0.90),0.91(0.88,0.95) | H-L拟合优度检验 | — |
| LIM等[ | 转化为分类变量 | 966 | 完整个案分析 | Logistic回归 | 文献回顾、单因素分析、向后逐步选择 | 内部验证 | 模型1:0.65(0.62,0.68)。模型2:0.75(0.72,0.77)。模型3:0.77(0.74,0.79) | H-L拟合优度检验 | 交叉验证 |
| YE等[ | 转化为分类变量 | 2 523 | 完整个案分析 | Logistic回归 | 多因素分析 | 内部验证 | 0.71(0.69,0.74) | H-L拟合优度检验 | 自举法、交叉验证 |
| XU等[ | 转化为分类变量 | — | 完整个案分析 | Logistic回归 | 单因素分析、多因素分析 | 内部验证 | 0.78(0.76,0.80) | 校准图 | 交叉验证 |
| NANRI等[ | 转化为分类变量 | 2 031 | 完整个案分析 | Logistic回归 | 向后逐步选择法 | 内部验证a、外部验证 | 模型1:0.717(0.703,0.731),0.734(0.715,0.753)。模型2:0.843(0.832,0.853),0.835(0.820,0.851)。模型3:0.827(0.816,0.838),0.819(0.803,0.835)。模型4:0.893(0.883,0.902),0.882(0.868,0.895) | H-L拟合优度检验、校准图 | — |
| WANG等[ | 转化为分类变量 | 8 766 | 完整个案分析 | Cox回归 | 逐步选择法 | 内部验证 | 模型1:0.66(0.65,0.68)。模型2:0.77(0.76,0.78) | 校准图 | 交叉验证 |
| LIU等[ | 转化为分类变量 | — | 完整个案分析 | 亚分布风险模型 | 单因素分析、多因素分析 | 内部验证 | 0.74(0.70,0.78) | 校准图 | 自举法 |
| MIYAKOSHI等[ | 转化为分类变量 | — | — | Cox回归 | 向后逐步选择法 | 内部验证a | 模型1:0.68(0.63,0.72)。模型2:0.75(0.70,0.78)。模型3:0.80(0.76,0.84) | H-L拟合优度检验、校准图 | — |
| ZHANG等[ | 保持连续性 | 4 032 | — | Cox回归 | 文献回顾 | 内部验证 | 0.77(0.76,0.78) | H-L拟合优度检验 | 交叉验证 |
| CHEN等[ | 转化为分类变量 | D:1 899 V:1 205 | 完整个案分析 | Cox回归 | 逐步选择法 | 内部验证 | 模型1:0.72(0.69,0.75)。模型2:0.77(0.74,0.80) | H-L拟合优度检验 | 自举法 |
| ZHANG等[ | 转化为分类变量 | 2 932 | 完整个案分析 | Cox回归 | 单因素分析、多因素分析 | 内部验证a | 模型1:0.67(0.66,0.68)。模型2:0.66(0.65,0.67)。模型3:0.68(0.67,0.69)。模型4:0.79(0.78,0.80) | 校准图 | — |
| WEN等[ | 转化为分类变量 | 1 014 | 完整个案分析 | Logistic回归 | 文献回顾、逐步选择法 | 内部验证a | 0.72(0.67,0.76) | H-L拟合优度检验 | — |
| YATSUYA等[ | 转化为分类变量 | 341 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 内部验证 | 0.77(C指数) | H-L拟合优度检验、校准图 | 交叉验证 |
| HA等[ | 部分转化为分类变量 | — | — | Cox回归 | 文献回顾、逐步选择法 | 外部验证 | 模型(男):0.71(0.70,0.73),0.63(0.53,0.73)。模型(女):0.76(0.75,0.78),0.66(0.55,0.76) | 校准图 | — |
| HAN等[ | 转化为分类变量 | 3 326 | 完整个案分析 | Cox回归 | 逐步选择法 | 内部验证 | 0.75(0.74,0.76) | — | 交叉验证 |
| HU等[ | 转化为分类变量 | 1 892 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 内部验证a | 模型1:0.73(0.72,0.74)。模型2:0.89(0.89,0.90) | 校准图 | — |
| WANG等[ | 保持连续性 | D:913 V:385 | 完整个案分析 | Logistic回归、矩阵多项式 | 逐步选择法 | 内部验证、外部验证 | 模型1:女,0.86(0.84,0.89)、0.84(0.80,0.89);男,0.75 (0.73,0.78)、0.75(0.72,0.80)。模型2:女,0.86(0.84,0.89)、0.86(0.82,0.90);男,0.78(0.76,0.80)、0.77(0.73,0.91)。模型3:女,0.86(0.84,0.89)、0.84(0.80,0.89);男,0.75(0.73,0.77)、0.76(0.72,0.79) | 校准图 | 自举法 |
| GUNTHER等[ | 转化为分类变量 | 126 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 内部验证a | 0.84(0.82,0.87) | — | — |
| SHAO等[ | 转化为分类变量 | — | 完整个案分析 | Logistic回归 | LASSO回归 | 内部验证、外部验证 | 模型1:0.79(0.76,0.82),0.82(0.78,0.86) 。模型2:0.81(0.78,0.83),0.82(0.78,0.87)。模型3:0.91(0.88,0.93),0.92(0.88,0.95) 。模型4:0.88(0.85,0.91),0.86(0.81,0.91) | 校准图 | 自举法 |
| ASGARI等[ | 保持连续性 | — | 单一插补 | Cox回归、基于混合效应模型和Cox模型的纵向和生存数据联合模型 | 文献回顾 | 内部验证、外部验证 | 模型1:0.85(0.82,0.89)。模型2:0.85(0.84,0.86)。模型3:0.84(0.83,0.85) | H-L拟合优度检验、校准图 | 自举法 |
| OH等[ | 转化为分类变量 | 3 059 | 完整个案分析 | Logistic回归 | 单因素分析、多因素分析 | 内部验证 | 模型1:0.66(0.63,0.72)。模型2:0.69(0.66,0.72)。模型3:0.75(0.72,0.78) | — | 交叉验证 |
| RHEE等[ | 转化为分类变量 | — | 多重插补 | Cox回归 | 逐步选择法 | 内部验证a | 0.84(0.83,0.85) | H-L拟合优度检验 | — |
表2 亚洲T2MD发病风险预测模型建立和验证的基本特征
Table 2 Basic characteristics of development and validation included risk prediction models for T2DM in Asian adults
| 第一作者 | 连续变量处理方法 | 缺失数据 | 建模方法 | 变量选择方法 | 验模方法 | AUC(95%CI) | 拟合优度 | 过度拟合情况 | |
|---|---|---|---|---|---|---|---|---|---|
| 数量 | 处理方法 | ||||||||
| AEKPLAKORN等[ | 转化为分类变量 | D:587 V:459 | 完整个案分析 | Logistic回归 | 单因素分析、多因素分析 | 外部验证 | 模型1:0.74(0.71,0.78),0.75(0.71,0.80)。模型2:0.76(0.72,0.79)。模型3:0.78(0.75,0.81)。模型4:0.79(0.75,0.82)。模型5:0.79(0.76,0.82) | H-L拟合优度检验 | — |
| CHIEN等[ | 转化为分类变量 | — | 完整个案分析 | Cox回归 | 向前逐步选择法 | 内部验证 | 模型1:0.70(0.68,0.73)。模型2:0.65(0.62,0.67) | H-L拟合优度检验 | 交叉验证、自举法 |
| GAO等[ | 转化为分类变量 | — | 完整个案分析 | Cox回归 | — | 内部验证a | 模型1:男,0.62(0.56,0.68);女,0.64(0.59,0.69)。模型2:男,0.70(0.64,0.75);女,0.71(0.66,0.76)。模型3:男,0.71(0.66,0.77);女,0.71(0.66,0.76) | — | — |
| SUN等[ | 转化为分类变量 | — | — | Cox回归 | 逐步选择法 | 内部验证a | 模型1:0.751(0.730,0.773)。模型2:0.848(0.828,0.867)。模型3:0.853(0.834,0.872)。模型4:0.838(0.818,0.858)。模型5:0.843(0.824,0.863) | H-L拟合优度检验 | — |
| CHUANG等[ | 转化为分类变量 | — | — | Cox回归 | 逐步选择法 | 内部验证a | 模型1:0.71(0.70,0.73)。模型2:0.75(0.73,0.78)。模型3:0.72(0.71,0.74)。模型4:0.76(0.73,0.79)。模型5:0.82(0.81,0.83)。模型6:0.84(0.81,0.86) | — | — |
| BOZORGMANESH等[ | 转化为分类变量 | 1 776 | 完整个案分析 | Logistic回归 | 向前逐步选择法 | 内部验证 | 模型1:0.75(0.72,0.78)。模型2:0.85(0.82,0.87)。模型3:0.85(0.82,0.87) | H-L拟合优度检验 | 自举法 |
| LIU等[ | 转化为分类变量 | — | — | Logistic回归 | 单因素分析、多因素分析 | 外部验证 | 模型1:0.68(0.65,0.72)。模型2:0.71(0.68,0.75)。模型3:0.72(0.69,0.76) | — | — |
| ONAT等[ | 转化为分类变量 | — | — | Cox回归 | 向后逐步选择法 | 内部验证a | 男:0.78(0.74,0.83)。女:0.77(0.73,0.82) | — | — |
| DOI等[ | 转化为分类变量 | D:194 V:144 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 外部验证 | 模型1:0.70(0.67,0.73),0.69(0.63,0.75)。模型2:0.78(0.74,0.80),0.78(0.73,0.83) | H-L拟合优度检验 | — |
| HEIANZA等[ | 部分转化为分类变量 | D:137 V:15 | 完整个案分析 | Logistic回归 | 向前逐步选择法 | 外部验证 | 模型1:0.71(0.68,0.74),0.73(0.67,0.78)。模型2:0.84(0.82,0.86),0.87(0.83,0.90)。模型3:0.84(0.82,0.86),0.88(0.84,0.92)。模型4:0.89(0.87,0.90),0.91(0.88,0.95) | H-L拟合优度检验 | — |
| LIM等[ | 转化为分类变量 | 966 | 完整个案分析 | Logistic回归 | 文献回顾、单因素分析、向后逐步选择 | 内部验证 | 模型1:0.65(0.62,0.68)。模型2:0.75(0.72,0.77)。模型3:0.77(0.74,0.79) | H-L拟合优度检验 | 交叉验证 |
| YE等[ | 转化为分类变量 | 2 523 | 完整个案分析 | Logistic回归 | 多因素分析 | 内部验证 | 0.71(0.69,0.74) | H-L拟合优度检验 | 自举法、交叉验证 |
| XU等[ | 转化为分类变量 | — | 完整个案分析 | Logistic回归 | 单因素分析、多因素分析 | 内部验证 | 0.78(0.76,0.80) | 校准图 | 交叉验证 |
| NANRI等[ | 转化为分类变量 | 2 031 | 完整个案分析 | Logistic回归 | 向后逐步选择法 | 内部验证a、外部验证 | 模型1:0.717(0.703,0.731),0.734(0.715,0.753)。模型2:0.843(0.832,0.853),0.835(0.820,0.851)。模型3:0.827(0.816,0.838),0.819(0.803,0.835)。模型4:0.893(0.883,0.902),0.882(0.868,0.895) | H-L拟合优度检验、校准图 | — |
| WANG等[ | 转化为分类变量 | 8 766 | 完整个案分析 | Cox回归 | 逐步选择法 | 内部验证 | 模型1:0.66(0.65,0.68)。模型2:0.77(0.76,0.78) | 校准图 | 交叉验证 |
| LIU等[ | 转化为分类变量 | — | 完整个案分析 | 亚分布风险模型 | 单因素分析、多因素分析 | 内部验证 | 0.74(0.70,0.78) | 校准图 | 自举法 |
| MIYAKOSHI等[ | 转化为分类变量 | — | — | Cox回归 | 向后逐步选择法 | 内部验证a | 模型1:0.68(0.63,0.72)。模型2:0.75(0.70,0.78)。模型3:0.80(0.76,0.84) | H-L拟合优度检验、校准图 | — |
| ZHANG等[ | 保持连续性 | 4 032 | — | Cox回归 | 文献回顾 | 内部验证 | 0.77(0.76,0.78) | H-L拟合优度检验 | 交叉验证 |
| CHEN等[ | 转化为分类变量 | D:1 899 V:1 205 | 完整个案分析 | Cox回归 | 逐步选择法 | 内部验证 | 模型1:0.72(0.69,0.75)。模型2:0.77(0.74,0.80) | H-L拟合优度检验 | 自举法 |
| ZHANG等[ | 转化为分类变量 | 2 932 | 完整个案分析 | Cox回归 | 单因素分析、多因素分析 | 内部验证a | 模型1:0.67(0.66,0.68)。模型2:0.66(0.65,0.67)。模型3:0.68(0.67,0.69)。模型4:0.79(0.78,0.80) | 校准图 | — |
| WEN等[ | 转化为分类变量 | 1 014 | 完整个案分析 | Logistic回归 | 文献回顾、逐步选择法 | 内部验证a | 0.72(0.67,0.76) | H-L拟合优度检验 | — |
| YATSUYA等[ | 转化为分类变量 | 341 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 内部验证 | 0.77(C指数) | H-L拟合优度检验、校准图 | 交叉验证 |
| HA等[ | 部分转化为分类变量 | — | — | Cox回归 | 文献回顾、逐步选择法 | 外部验证 | 模型(男):0.71(0.70,0.73),0.63(0.53,0.73)。模型(女):0.76(0.75,0.78),0.66(0.55,0.76) | 校准图 | — |
| HAN等[ | 转化为分类变量 | 3 326 | 完整个案分析 | Cox回归 | 逐步选择法 | 内部验证 | 0.75(0.74,0.76) | — | 交叉验证 |
| HU等[ | 转化为分类变量 | 1 892 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 内部验证a | 模型1:0.73(0.72,0.74)。模型2:0.89(0.89,0.90) | 校准图 | — |
| WANG等[ | 保持连续性 | D:913 V:385 | 完整个案分析 | Logistic回归、矩阵多项式 | 逐步选择法 | 内部验证、外部验证 | 模型1:女,0.86(0.84,0.89)、0.84(0.80,0.89);男,0.75 (0.73,0.78)、0.75(0.72,0.80)。模型2:女,0.86(0.84,0.89)、0.86(0.82,0.90);男,0.78(0.76,0.80)、0.77(0.73,0.91)。模型3:女,0.86(0.84,0.89)、0.84(0.80,0.89);男,0.75(0.73,0.77)、0.76(0.72,0.79) | 校准图 | 自举法 |
| GUNTHER等[ | 转化为分类变量 | 126 | 完整个案分析 | Cox回归 | 向后逐步选择法 | 内部验证a | 0.84(0.82,0.87) | — | — |
| SHAO等[ | 转化为分类变量 | — | 完整个案分析 | Logistic回归 | LASSO回归 | 内部验证、外部验证 | 模型1:0.79(0.76,0.82),0.82(0.78,0.86) 。模型2:0.81(0.78,0.83),0.82(0.78,0.87)。模型3:0.91(0.88,0.93),0.92(0.88,0.95) 。模型4:0.88(0.85,0.91),0.86(0.81,0.91) | 校准图 | 自举法 |
| ASGARI等[ | 保持连续性 | — | 单一插补 | Cox回归、基于混合效应模型和Cox模型的纵向和生存数据联合模型 | 文献回顾 | 内部验证、外部验证 | 模型1:0.85(0.82,0.89)。模型2:0.85(0.84,0.86)。模型3:0.84(0.83,0.85) | H-L拟合优度检验、校准图 | 自举法 |
| OH等[ | 转化为分类变量 | 3 059 | 完整个案分析 | Logistic回归 | 单因素分析、多因素分析 | 内部验证 | 模型1:0.66(0.63,0.72)。模型2:0.69(0.66,0.72)。模型3:0.75(0.72,0.78) | — | 交叉验证 |
| RHEE等[ | 转化为分类变量 | — | 多重插补 | Cox回归 | 逐步选择法 | 内部验证a | 0.84(0.83,0.85) | H-L拟合优度检验 | — |
| 第一作者 | 模型包含的预测因子 | 模型呈现形式 | 局限性(模型/研究) |
|---|---|---|---|
| AEKPLAKORN等[ | 模型1(5个):年龄、BMI、腰围、高血压、FHDM。模型2(6个):模型1中的因子+FBG 。模型3(6个):模型1中的因子+IGT。模型4(7个):模型3中的因子+TG。模型5(8个):模型4中的因子+HDL-C | 根据各因子回归系数的大小给其分配分值,计算个体的发病风险总分 | — |
| CHIEN等[ | 模型1(6个):年龄、FBG、BMI、TG、白细胞计数、HDL-C。模型2(5个):年龄、性别、BMI、FHDM、降压药物治疗 | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 研究对象年龄较大;糖尿病诊断方法单一 |
| GAO等[ | 模型1(3个):BMI、腰围、FHDM。模型2(4个):模型1中的因子+FBG。模型3(5个):模型1中的因子+收缩压、TG | 根据各因子回归系数、基础风险率,计算个体发病概率 | 预测能力中等;缺乏外部验证 |
| SUN等[ | 模型1(8个):受教育程度、年龄、FHDM、吸烟、运动、高血压、BMI、腰围。模型2(9个):年龄、性别、受教育程度、吸烟、BMI、腰围、FHDM、高血压、FBG。模型3(13个):模型2中的因子+TG、HDL-C、ALT、eGFR。模型4(7个):性别、种族、FHDM、FBG、收缩压、腰围、身高。模型5(8个):年龄、种族、FBG、收缩压、腰围、身高、HDL-C、TG | 根据各因子的回归系数,得出发病风险得分的计算公式 | 基线时未进行葡萄糖耐量试验;无来自社区的样本;未证实其在年轻人T2DM发病风险预测中的应用效果 |
| CHUANG等[ | 模型1(6个):年龄、性别、饮酒习惯、受教育程度、BMI、腰围。模型2(7个):模型1中的因子+FHDM。模型3(7个):模型1中的因子+高血压。模型4(8个):模型3中的因子+FHDM。模型5(9个):模型3中的因子+TG、FBG。模型6(10个):模型5中的因子+FHDM | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 未将葡萄糖耐量试验纳入T2DM诊断标准,可能会造成漏诊 |
| BOZORGMANESH等[ | 模型1(5个):年龄、收缩压、FHMD、腰臀比、腰高比。模型2(6个):收缩压、FHMD、腰臀比、腰高比、TG/HDL-C、FBG。模型3(7个):收缩压、FHMD、腰臀比、腰高比、TG/HDL-C、FBG、2 h-PG | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 缺少外部验证 |
| LIU等[ | 模型1(4个):年龄、高血压、FHDM、BMI。模型2(5个):模型1中的因子+FBG。模型3(6个):年龄、高血压、高血糖、FHDM、BMI、FBG | 以取整后的OR作为各因子的分值,计算个体的发病风险总分 | 未证实其在年轻人T2DM发病风险预测中的应用效果 |
| ONAT等[ | 7个:FHDM、体育活动、年龄、腰围、FBG、C反应蛋白、HDL-C | 根据各因子的回归系数、HR对其进行赋分,计算个体的发病风险总分 | — |
| DOI等[ | 模型1(8个):年龄、性别、FHDM、腹围、BMI、高血压、定期运动、经常吸烟。模型2(9个):模型1中的因子+FBG | 以取整后的回归系数作为各因子的分值,计算个体的发病风险总分 | 预测能力一般;存在自我报告偏倚;预测短期内T2DM发病风险的能力有待考量 |
| HEIANZA等[ | 模型1(5个):年龄、性别、FHDM、吸烟、BMI。模型2(6个):模型1中的因子+FBG。模型3(6个):模型1中的因子+HbA1c。模型4(7个):模型1中的因子+FBG+HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 研究对象主要为男性,在其他人群T2DM发病风险预测中的应用效果有待进一步研究 |
| LIM等[ | 模型1(5个):年龄、FHDM、当前吸烟情况、BMI、高血压。模型2(8个):模型1中的因子+FBG、HDL-C、TG。模型3(9个):模型2中的因子+HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 模型可能只适用于临床环境或流行病学研究 |
| YE等[ | 6个:性别、BMI、FBG、HbA1c、高血压、C反应蛋白 | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 未进行外部验证 |
| XU等[ | 7个:年龄、性别、FHDM、BMI、FBG、HDL、TG | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 将FBG作为判断基线时糖尿病患病情况的指标,可能造成糖尿病患病率被低估;数据缺失率约38%;在其他民族/年轻人T2DM发病风险预测中的应用效果有待进一步研究 |
| NANRI等[ | 模型1(6个):年龄、性别、BMI、腰围、高血压、吸烟情况。模型2(7个):模型1中的因子+FBG。模型3(7个):模型1中的因子+HbA1c。模型4(8个):模型1中的因子+ FBG、HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 可能存在选择偏倚 |
| WANG等[ | 模型1(7个):年龄、性别、BMI、FHDM、受教育程度、血压、静息心率。模型2(10个):模型1中的因子+FBG、TG、调脂药物使用情况 | 列线图,读取各因子的值对应的得分,将所有因子的得分相加 | 预测能力有限;在其他人群T2DM发病风险预测中的应用效果有待进一步研究 |
| LIU等[ | 5个:年龄、BMI、FBG、自评健康状况、体育活动 | — | 样本量较少 |
| MIYAKOSHI等[ | 模型1(5个):性别、FHDM、年龄、收缩压、BMI。模型2(7个):性别、FHDM、年龄、收缩压、FPG、HbA1c、TG。模型3(11个):吸烟状况、体育活动、年龄、收缩压、BMI、性别、FPG、2 h-PG、HbA1c、HDL-C、TG | 以取整后的HR作为各因子的分值,计算个体的发病风险总分 | 回顾性研究;未进行外部验证 |
| ZHANG等[ | 4个:年龄、BMI、TG、FBG | 将各因子的回归系数×100后取整,以此作为各因子的分值,计算个体的发病风险总分 | 数据缺失率较高,可能导致偏倚;在其他人群T2DM发病风险预测中的应用效果有待进一步研究 |
| CHEN等[ | 模型1(6个):年龄、超重、肥胖、FHDM、饮食以肉类为主、高血压。模型2(7个):模型1中的因子+FBG | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 失访人数较多;在不同环境中的预测能力需进一步测试 |
| ZHANG等[ | 模型1(7个):年龄、吸烟、饮茶频率、体育活动水平、FHDM、BMI、高血压。模型2(7个):年龄、吸烟、饮茶频率、体育活动水平、FHDM、腰高比、高血压。模型3(8个):模型1中的因子+腰高比。模型4(10个):模型3中的因子+TG、FBG | 将各因子的回归系数×10,以此作为各因子的分值,计算个体的发病风险总分 | 未进行外部验证 |
| WEN等[ | 4个:年龄、BMI、腰围、FHDM | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 缺失数据较多,可能导致偏倚 |
| YATSUYA等[ | 6个:年龄、BMI、吸烟状况、FHDM、TG、FBG | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 样本皆为男性且其职业以公务员为主,在其他人群T2DM发病风险预测中的应用效果有待进一步验证 |
| HA等[ | 11个:年龄、FHDM、吸烟状况、体育活动水平、抗高血压治疗、他汀类药物使用、BMI、收缩压、总胆固醇、FBG为共性因子,γ-谷氨酰转移酶(只限女性)、酒精摄入(只限男性)为性别特异性因子 | 根据各因子的回归系数,得出发病风险的计算公式 | 外部验证队列的校准图显示,T2DM发病风险被低估 |
| HAN等[ | 6个:BMI、FBG、高血压、高脂血症、当前吸烟状况、FHDM | 将各因子的回归系数×10,以此作为各因子的分值,计算个体的发病风险总分 | 未限制研究人群年龄,未进行外部验证 |
| HU等[ | 模型1(6个):年龄、性别、腹部肥胖、BMI、吸烟状况、高血压。模型2(8个):模型1中的因子+血脂异常、FBG | 根据各因子回归系数、基础风险率,计算个体发病概率 | 样本来源受到限制,主要为大公司职员;模型无法区分糖尿病的类型 |
| WANG等[ | 模型1(6个):年龄、BMI、FBG、HDL-C、LDL-C、TG。模型2:男(5个),年龄、TG、FBG、LDL-C、BMI;女(6个),年龄、TG、FBG、HDL-C、LDL-C、BMI。模型3(8个):年龄、BMI、FBG、收缩压、舒张压、HDL-C、LDL-C、TG | 列线图,读取各因子的值对应的得分,将所有因子的得分相加 | — |
| GUNTHER等[ | 17个:年龄、性别、种族、身高、腰围、FHDM、收缩压、FBG、TG、HDL-C、C8-DC、C16-OH、异亮氨酸/亮氨酸、鸟氨酸、脯氨酸、丝氨酸、丙氨酸/甘氨酸 | — | 未进行外部验证 |
| SHAO等[ | 模型1(8个):年龄、性别、民族、高血压、吸烟、饮酒、腰围、BMI。模型2(17个):模型1中的因子+受教育程度、软饮料和茶摄入、体育活动、能量摄入、碳水化合物摄入、脂肪摄入、蛋白质摄入、三头肌皮褶厚度、睡眠时间。模型3(24个):模型2中的因子+LDL-C、HDL-C、TC、TG、胰岛素、FBG、HbA1c 。模型4(7个):LDL-C、HDL-C、TC、TG、胰岛素、FBG、HbA1c | 列线图,读取各因子的值对应的得分,将所有因子的得分相加 | 当预测概率<0.20时,T2DM发病风险可能会被低估 |
| ASGARI等[ | 模型1(6个):年龄、身高、收缩压、TG、HDL-C、FHDM。模型2(7个):模型1中的因子+FBG。模型3(7个):模型1中的因子+腰围 | 根据各因子的回归系数,得出发病风险得分的计算公式 | 使用中间日期来定义事件日期 |
| OH等[ | 模型1(6个):年龄、居住地、吸烟、高血压、FHDM、腰围。模型2(7个):模型1中的因子+FBG;模型3(7个):模型1中的因子+HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 模型需进一步被验证 |
| RHEE等[ | 17个:年龄、性别、BMI、收缩压、舒张压、FBG、TC、HbA1c、天冬氨酸氨基转移酶、丙氨酸氨基转移酶、γ-谷氨酰转移酶、蛋白尿、吸烟、饮酒、锻炼、个人史、家族史 | — | — |
表3 亚洲T2MD发病风险预测模型的预测因子、呈现形式及其局限性
Table 3 Predictors,presentation and limitations of included risk prediction models for T2DM in Asian adults
| 第一作者 | 模型包含的预测因子 | 模型呈现形式 | 局限性(模型/研究) |
|---|---|---|---|
| AEKPLAKORN等[ | 模型1(5个):年龄、BMI、腰围、高血压、FHDM。模型2(6个):模型1中的因子+FBG 。模型3(6个):模型1中的因子+IGT。模型4(7个):模型3中的因子+TG。模型5(8个):模型4中的因子+HDL-C | 根据各因子回归系数的大小给其分配分值,计算个体的发病风险总分 | — |
| CHIEN等[ | 模型1(6个):年龄、FBG、BMI、TG、白细胞计数、HDL-C。模型2(5个):年龄、性别、BMI、FHDM、降压药物治疗 | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 研究对象年龄较大;糖尿病诊断方法单一 |
| GAO等[ | 模型1(3个):BMI、腰围、FHDM。模型2(4个):模型1中的因子+FBG。模型3(5个):模型1中的因子+收缩压、TG | 根据各因子回归系数、基础风险率,计算个体发病概率 | 预测能力中等;缺乏外部验证 |
| SUN等[ | 模型1(8个):受教育程度、年龄、FHDM、吸烟、运动、高血压、BMI、腰围。模型2(9个):年龄、性别、受教育程度、吸烟、BMI、腰围、FHDM、高血压、FBG。模型3(13个):模型2中的因子+TG、HDL-C、ALT、eGFR。模型4(7个):性别、种族、FHDM、FBG、收缩压、腰围、身高。模型5(8个):年龄、种族、FBG、收缩压、腰围、身高、HDL-C、TG | 根据各因子的回归系数,得出发病风险得分的计算公式 | 基线时未进行葡萄糖耐量试验;无来自社区的样本;未证实其在年轻人T2DM发病风险预测中的应用效果 |
| CHUANG等[ | 模型1(6个):年龄、性别、饮酒习惯、受教育程度、BMI、腰围。模型2(7个):模型1中的因子+FHDM。模型3(7个):模型1中的因子+高血压。模型4(8个):模型3中的因子+FHDM。模型5(9个):模型3中的因子+TG、FBG。模型6(10个):模型5中的因子+FHDM | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 未将葡萄糖耐量试验纳入T2DM诊断标准,可能会造成漏诊 |
| BOZORGMANESH等[ | 模型1(5个):年龄、收缩压、FHMD、腰臀比、腰高比。模型2(6个):收缩压、FHMD、腰臀比、腰高比、TG/HDL-C、FBG。模型3(7个):收缩压、FHMD、腰臀比、腰高比、TG/HDL-C、FBG、2 h-PG | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 缺少外部验证 |
| LIU等[ | 模型1(4个):年龄、高血压、FHDM、BMI。模型2(5个):模型1中的因子+FBG。模型3(6个):年龄、高血压、高血糖、FHDM、BMI、FBG | 以取整后的OR作为各因子的分值,计算个体的发病风险总分 | 未证实其在年轻人T2DM发病风险预测中的应用效果 |
| ONAT等[ | 7个:FHDM、体育活动、年龄、腰围、FBG、C反应蛋白、HDL-C | 根据各因子的回归系数、HR对其进行赋分,计算个体的发病风险总分 | — |
| DOI等[ | 模型1(8个):年龄、性别、FHDM、腹围、BMI、高血压、定期运动、经常吸烟。模型2(9个):模型1中的因子+FBG | 以取整后的回归系数作为各因子的分值,计算个体的发病风险总分 | 预测能力一般;存在自我报告偏倚;预测短期内T2DM发病风险的能力有待考量 |
| HEIANZA等[ | 模型1(5个):年龄、性别、FHDM、吸烟、BMI。模型2(6个):模型1中的因子+FBG。模型3(6个):模型1中的因子+HbA1c。模型4(7个):模型1中的因子+FBG+HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 研究对象主要为男性,在其他人群T2DM发病风险预测中的应用效果有待进一步研究 |
| LIM等[ | 模型1(5个):年龄、FHDM、当前吸烟情况、BMI、高血压。模型2(8个):模型1中的因子+FBG、HDL-C、TG。模型3(9个):模型2中的因子+HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 模型可能只适用于临床环境或流行病学研究 |
| YE等[ | 6个:性别、BMI、FBG、HbA1c、高血压、C反应蛋白 | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 未进行外部验证 |
| XU等[ | 7个:年龄、性别、FHDM、BMI、FBG、HDL、TG | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 将FBG作为判断基线时糖尿病患病情况的指标,可能造成糖尿病患病率被低估;数据缺失率约38%;在其他民族/年轻人T2DM发病风险预测中的应用效果有待进一步研究 |
| NANRI等[ | 模型1(6个):年龄、性别、BMI、腰围、高血压、吸烟情况。模型2(7个):模型1中的因子+FBG。模型3(7个):模型1中的因子+HbA1c。模型4(8个):模型1中的因子+ FBG、HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 可能存在选择偏倚 |
| WANG等[ | 模型1(7个):年龄、性别、BMI、FHDM、受教育程度、血压、静息心率。模型2(10个):模型1中的因子+FBG、TG、调脂药物使用情况 | 列线图,读取各因子的值对应的得分,将所有因子的得分相加 | 预测能力有限;在其他人群T2DM发病风险预测中的应用效果有待进一步研究 |
| LIU等[ | 5个:年龄、BMI、FBG、自评健康状况、体育活动 | — | 样本量较少 |
| MIYAKOSHI等[ | 模型1(5个):性别、FHDM、年龄、收缩压、BMI。模型2(7个):性别、FHDM、年龄、收缩压、FPG、HbA1c、TG。模型3(11个):吸烟状况、体育活动、年龄、收缩压、BMI、性别、FPG、2 h-PG、HbA1c、HDL-C、TG | 以取整后的HR作为各因子的分值,计算个体的发病风险总分 | 回顾性研究;未进行外部验证 |
| ZHANG等[ | 4个:年龄、BMI、TG、FBG | 将各因子的回归系数×100后取整,以此作为各因子的分值,计算个体的发病风险总分 | 数据缺失率较高,可能导致偏倚;在其他人群T2DM发病风险预测中的应用效果有待进一步研究 |
| CHEN等[ | 模型1(6个):年龄、超重、肥胖、FHDM、饮食以肉类为主、高血压。模型2(7个):模型1中的因子+FBG | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 失访人数较多;在不同环境中的预测能力需进一步测试 |
| ZHANG等[ | 模型1(7个):年龄、吸烟、饮茶频率、体育活动水平、FHDM、BMI、高血压。模型2(7个):年龄、吸烟、饮茶频率、体育活动水平、FHDM、腰高比、高血压。模型3(8个):模型1中的因子+腰高比。模型4(10个):模型3中的因子+TG、FBG | 将各因子的回归系数×10,以此作为各因子的分值,计算个体的发病风险总分 | 未进行外部验证 |
| WEN等[ | 4个:年龄、BMI、腰围、FHDM | 基于各因子的回归系数及其参考值得出各因子的分值,计算个体的发病风险总分 | 缺失数据较多,可能导致偏倚 |
| YATSUYA等[ | 6个:年龄、BMI、吸烟状况、FHDM、TG、FBG | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 样本皆为男性且其职业以公务员为主,在其他人群T2DM发病风险预测中的应用效果有待进一步验证 |
| HA等[ | 11个:年龄、FHDM、吸烟状况、体育活动水平、抗高血压治疗、他汀类药物使用、BMI、收缩压、总胆固醇、FBG为共性因子,γ-谷氨酰转移酶(只限女性)、酒精摄入(只限男性)为性别特异性因子 | 根据各因子的回归系数,得出发病风险的计算公式 | 外部验证队列的校准图显示,T2DM发病风险被低估 |
| HAN等[ | 6个:BMI、FBG、高血压、高脂血症、当前吸烟状况、FHDM | 将各因子的回归系数×10,以此作为各因子的分值,计算个体的发病风险总分 | 未限制研究人群年龄,未进行外部验证 |
| HU等[ | 模型1(6个):年龄、性别、腹部肥胖、BMI、吸烟状况、高血压。模型2(8个):模型1中的因子+血脂异常、FBG | 根据各因子回归系数、基础风险率,计算个体发病概率 | 样本来源受到限制,主要为大公司职员;模型无法区分糖尿病的类型 |
| WANG等[ | 模型1(6个):年龄、BMI、FBG、HDL-C、LDL-C、TG。模型2:男(5个),年龄、TG、FBG、LDL-C、BMI;女(6个),年龄、TG、FBG、HDL-C、LDL-C、BMI。模型3(8个):年龄、BMI、FBG、收缩压、舒张压、HDL-C、LDL-C、TG | 列线图,读取各因子的值对应的得分,将所有因子的得分相加 | — |
| GUNTHER等[ | 17个:年龄、性别、种族、身高、腰围、FHDM、收缩压、FBG、TG、HDL-C、C8-DC、C16-OH、异亮氨酸/亮氨酸、鸟氨酸、脯氨酸、丝氨酸、丙氨酸/甘氨酸 | — | 未进行外部验证 |
| SHAO等[ | 模型1(8个):年龄、性别、民族、高血压、吸烟、饮酒、腰围、BMI。模型2(17个):模型1中的因子+受教育程度、软饮料和茶摄入、体育活动、能量摄入、碳水化合物摄入、脂肪摄入、蛋白质摄入、三头肌皮褶厚度、睡眠时间。模型3(24个):模型2中的因子+LDL-C、HDL-C、TC、TG、胰岛素、FBG、HbA1c 。模型4(7个):LDL-C、HDL-C、TC、TG、胰岛素、FBG、HbA1c | 列线图,读取各因子的值对应的得分,将所有因子的得分相加 | 当预测概率<0.20时,T2DM发病风险可能会被低估 |
| ASGARI等[ | 模型1(6个):年龄、身高、收缩压、TG、HDL-C、FHDM。模型2(7个):模型1中的因子+FBG。模型3(7个):模型1中的因子+腰围 | 根据各因子的回归系数,得出发病风险得分的计算公式 | 使用中间日期来定义事件日期 |
| OH等[ | 模型1(6个):年龄、居住地、吸烟、高血压、FHDM、腰围。模型2(7个):模型1中的因子+FBG;模型3(7个):模型1中的因子+HbA1c | 根据各因子的回归系数对其进行赋分,计算个体的发病风险总分 | 模型需进一步被验证 |
| RHEE等[ | 17个:年龄、性别、BMI、收缩压、舒张压、FBG、TC、HbA1c、天冬氨酸氨基转移酶、丙氨酸氨基转移酶、γ-谷氨酰转移酶、蛋白尿、吸烟、饮酒、锻炼、个人史、家族史 | — | — |
| 第一作者 | 研究对象领域偏倚风险 | 预测因子领域偏倚风险 | 结果领域偏倚风险 | 数据分析领域偏倚风险 | 总体偏倚风险 | 适用性 | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ① | ② | 风险评价 | ③ | ④ | ⑤ | 风险评价 | ⑥ | ⑦ | ⑧ | ⑨ | ⑩ | ⑪ | 风险评价 | ⑫ | ⑬ | ⑭ | ⑮ | ⑯ | ⑰ | ⑱ | ⑲ | ⑳ | 风险评价 | 研究对象领域 | 预测因子领域 | 结果领域 | 总体评价 | ||
| AEKPLAKORN等[ | Y | Y | L | PY | PY | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | Y | N | — | Y | — | Y | H | H | L | L | L | L |
| CHIEN等[ | Y | N | H | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | PN | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| GAO等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | — | Y | N | Y | — | N | — | Y | H | H | L | L | L | L |
| SUN等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | N | — | — | N | — | Y | H | H | L | L | L | L |
| CHUANG等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | — | Y | H | H | L | L | L | L |
| BOZORGMANESH等[ | Y | Y | L | Y | Y | Y | L | Y | Y | PY | Y | Y | Y | L | Y | N | N | PY | Y | — | Y | PY | Y | H | H | L | L | L | L |
| LIU等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | N | — | N | — | Y | H | H | L | L | L | L |
| ONAT等[ | Y | Y | L | Y | Y | Y | L | Y | Y | PN | Y | Y | Y | H | Y | N | Y | — | Y | — | N | — | Y | H | H | L | L | L | L |
| DOI等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | N | Y | — | Y | — | Y | H | H | L | L | L | L |
| HEIANZA等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | N | N | Y | — | N | — | N | H | H | L | L | L | L |
| LIM等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | N | — | N | PY | Y | H | H | L | L | L | L |
| YE等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | PY | Y | Y | Y | — | N | Y | — | H | H | L | L | L | L |
| XU等[ | Y | Y | L | N | Y | Y | H | Y | Y | Y | Y | PY | Y | L | Y | N | Y | — | N | — | Y | PY | Y | H | H | L | L | L | L |
| NANRI等[ | Y | Y | L | N | Y | Y | H | PY | Y | Y | N | PY | Y | H | Y | N | N | N | Y | — | Y | — | — | H | H | L | L | L | L |
| WANG等[ | Y | Y | L | — | Y | Y | U | Y | Y | Y | Y | PY | Y | L | Y | Y | — | — | Y | — | Y | Y | Y | U | Ha | L | L | L | L |
| LIU等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | Y | N | Y | N | Y | — | H | H | L | L | L | L |
| MIYAKOSHI等[ | Y | Y | L | PY | PY | Y | L | Y | Y | Y | N | PY | Y | L | Y | Y | N | — | Y | — | Y | — | Y | H | H | L | L | L | L |
| ZHANG等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| CHEN等[ | Y | Y | L | PY | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | PY | N | Y | — | PN | Y | Y | U | Ha | L | L | L | L |
| ZHANG等[ | Y | Y | L | Y | Y | Y | L | Y | Y | N | Y | Y | — | H | Y | Y | Y | N | N | — | Y | — | Y | H | H | L | L | L | L |
| WEN等[ | Y | Y | L | PY | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | N | N | Y | — | Y | — | Y | H | H | L | L | L | L |
| YATSUYA等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | N | PY | Y | H | Y | Y | N | N | Y | — | Y | PY | Y | H | H | L | L | L | L |
| HA等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | Y | — | Y | H | H | L | L | L | L |
| HAN等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| HU等[ | Y | N | H | Y | Y | Y | L | PY | Y | Y | N | PY | Y | H | Y | Y | Y | N | Y | — | Y | — | N | H | H | L | L | L | L |
| WANG等[ | Y | N | H | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| GUNTHER等[ | PY | Y | L | Y | Y | Y | L | Y | Y | Y | Y | Y | Y | L | N | Y | N | N | Y | — | N | — | Y | H | H | L | L | L | L |
| SHAO等[ | Y | N | H | Y | Y | Y | L | PY | Y | Y | Y | PY | Y | L | Y | Y | N | N | Y | — | Y | PY | Y | H | H | L | L | L | L |
| ASGARI等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | Y | Y | L | Y | — | N | Y | Y | PY | Y | Y | Y | H | H | L | L | L | L |
| OH等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | N | PY | Y | H | Y | Y | Y | N | N | — | N | PY | Y | H | H | L | L | L | L |
| RHEE等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | Y | Y | — | Y | — | Y | U | H | L | L | L | L |
表4 纳入文献偏倚风险及适用性评价结果
Table 4 Results of the assessment of risk of bias and applicability of included studies on the risk prediction model of T2DM
| 第一作者 | 研究对象领域偏倚风险 | 预测因子领域偏倚风险 | 结果领域偏倚风险 | 数据分析领域偏倚风险 | 总体偏倚风险 | 适用性 | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ① | ② | 风险评价 | ③ | ④ | ⑤ | 风险评价 | ⑥ | ⑦ | ⑧ | ⑨ | ⑩ | ⑪ | 风险评价 | ⑫ | ⑬ | ⑭ | ⑮ | ⑯ | ⑰ | ⑱ | ⑲ | ⑳ | 风险评价 | 研究对象领域 | 预测因子领域 | 结果领域 | 总体评价 | ||
| AEKPLAKORN等[ | Y | Y | L | PY | PY | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | Y | N | — | Y | — | Y | H | H | L | L | L | L |
| CHIEN等[ | Y | N | H | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | PN | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| GAO等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | — | Y | N | Y | — | N | — | Y | H | H | L | L | L | L |
| SUN等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | N | — | — | N | — | Y | H | H | L | L | L | L |
| CHUANG等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | — | Y | H | H | L | L | L | L |
| BOZORGMANESH等[ | Y | Y | L | Y | Y | Y | L | Y | Y | PY | Y | Y | Y | L | Y | N | N | PY | Y | — | Y | PY | Y | H | H | L | L | L | L |
| LIU等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | N | — | N | — | Y | H | H | L | L | L | L |
| ONAT等[ | Y | Y | L | Y | Y | Y | L | Y | Y | PN | Y | Y | Y | H | Y | N | Y | — | Y | — | N | — | Y | H | H | L | L | L | L |
| DOI等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | N | Y | — | Y | — | Y | H | H | L | L | L | L |
| HEIANZA等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | N | N | Y | — | N | — | N | H | H | L | L | L | L |
| LIM等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | N | — | N | PY | Y | H | H | L | L | L | L |
| YE等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | PY | Y | Y | Y | — | N | Y | — | H | H | L | L | L | L |
| XU等[ | Y | Y | L | N | Y | Y | H | Y | Y | Y | Y | PY | Y | L | Y | N | Y | — | N | — | Y | PY | Y | H | H | L | L | L | L |
| NANRI等[ | Y | Y | L | N | Y | Y | H | PY | Y | Y | N | PY | Y | H | Y | N | N | N | Y | — | Y | — | — | H | H | L | L | L | L |
| WANG等[ | Y | Y | L | — | Y | Y | U | Y | Y | Y | Y | PY | Y | L | Y | Y | — | — | Y | — | Y | Y | Y | U | Ha | L | L | L | L |
| LIU等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | N | Y | Y | N | Y | N | Y | — | H | H | L | L | L | L |
| MIYAKOSHI等[ | Y | Y | L | PY | PY | Y | L | Y | Y | Y | N | PY | Y | L | Y | Y | N | — | Y | — | Y | — | Y | H | H | L | L | L | L |
| ZHANG等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| CHEN等[ | Y | Y | L | PY | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | PY | N | Y | — | PN | Y | Y | U | Ha | L | L | L | L |
| ZHANG等[ | Y | Y | L | Y | Y | Y | L | Y | Y | N | Y | Y | — | H | Y | Y | Y | N | N | — | Y | — | Y | H | H | L | L | L | L |
| WEN等[ | Y | Y | L | PY | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | N | N | Y | — | Y | — | Y | H | H | L | L | L | L |
| YATSUYA等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | N | PY | Y | H | Y | Y | N | N | Y | — | Y | PY | Y | H | H | L | L | L | L |
| HA等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | Y | — | Y | H | H | L | L | L | L |
| HAN等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| HU等[ | Y | N | H | Y | Y | Y | L | PY | Y | Y | N | PY | Y | H | Y | Y | Y | N | Y | — | Y | — | N | H | H | L | L | L | L |
| WANG等[ | Y | N | H | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | N | Y | — | N | PY | Y | H | H | L | L | L | L |
| GUNTHER等[ | PY | Y | L | Y | Y | Y | L | Y | Y | Y | Y | Y | Y | L | N | Y | N | N | Y | — | N | — | Y | H | H | L | L | L | L |
| SHAO等[ | Y | N | H | Y | Y | Y | L | PY | Y | Y | Y | PY | Y | L | Y | Y | N | N | Y | — | Y | PY | Y | H | H | L | L | L | L |
| ASGARI等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | Y | Y | L | Y | — | N | Y | Y | PY | Y | Y | Y | H | H | L | L | L | L |
| OH等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | N | PY | Y | H | Y | Y | Y | N | N | — | N | PY | Y | H | H | L | L | L | L |
| RHEE等[ | Y | Y | L | Y | Y | Y | L | Y | Y | Y | Y | PY | Y | L | Y | Y | Y | Y | Y | — | Y | — | Y | U | H | L | L | L | L |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
贺小宁,张雅雯,阮贞,等. 中国2型糖尿病患者慢性并发症患病率与次均医疗费用研究[J]. 中华内分泌代谢杂志,2019,35(3):6. DOI:10.3760/cma.j.issn.1000-6699.2019.03.004.
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [1] | 田晨, 刘佳宁, 田金徽, 葛龙. 动态系统评价制作方法与流程[J]. 中国全科医学, 2025, 28(30): 3853-3860. |
| [2] | 贾高鹏, 陈秋雨. 老年急性ST段抬高型心肌梗死经皮冠状动脉介入治疗术后心绞痛复发风险预测模型构建和验证:基于CYP2C19相关基因检测[J]. 中国全科医学, 2025, 28(30): 3779-3786. |
| [3] | 徐百川, 王艳, 张彭, 李艺婷, 刘飞来, 谢洋. 慢性阻塞性肺疾病共病肺癌筛查工具分析[J]. 中国全科医学, 2025, 28(30): 3847-3852. |
| [4] | 李玲, 李雅萍, 钱时兴, 聂婧, 陆春华, 李霞. 社区中老年人认知功能影响因素及风险预测研究[J]. 中国全科医学, 2025, 28(30): 3773-3778. |
| [5] | 张睿敏, 董哲毅, 李爽, 王倩, 陈香美. 基于肾活检病理诊断的糖尿病肾病中医相关因素研究[J]. 中国全科医学, 2025, 28(26): 3307-3313. |
| [6] | 刘银银, 隋鸿平, 李婷婷, 姜桐桐, 史铁英, 夏云龙. 乳腺癌治疗相关心脏毒性风险预测模型的研究进展[J]. 中国全科医学, 2025, 28(24): 3072-3078. |
| [7] | 吴莎, 张代义, 李晋, 宣勤考, 钱晓东, 朱传武, 浦剑虹, 朱莉. 基于体检队列的代谢相关脂肪性肝病与高血糖关联及联合预测模型构建研究[J]. 中国全科医学, 2025, 28(23): 2861-2869. |
| [8] | 周倩, 吴晓敏, 王宝华, 严若菡, 蔚苗, 吴静. 胃癌发生风险的列线图预测模型研究[J]. 中国全科医学, 2025, 28(23): 2870-2877. |
| [9] | 赵晓晴, 郭桐桐, 张欣怡, 李林虹, 张亚, 嵇丽红, 董志伟, 高倩倩, 蔡伟芹, 郑文贵, 井淇. 社区老年人认知障碍风险预测模型的构建与验证研究[J]. 中国全科医学, 2025, 28(22): 2776-2783. |
| [10] | 陈琳凤, 王晨霞, 贺金鹏. 糖尿病共同照护模式下门诊规律随访和院外APP活跃度对2型糖尿病患者代谢指标的影响研究[J]. 中国全科医学, 2025, 28(22): 2762-2768. |
| [11] | 王颖, 颜轶隽, 刘蕾, 胡毓敏, 张扬, 刘凯, 姜博仁. 抗阻力运动联合营养干预对老年2型糖尿病合并肌少症患者血糖稳定性影响的临床研究[J]. 中国全科医学, 2025, 28(21): 2604-2610. |
| [12] | 马盼盼, 王思静, 游娜, 丁大法, 鲁一兵. Danuglipron与Orforglipron治疗2型糖尿病疗效及安全性的Meta分析[J]. 中国全科医学, 2025, 28(21): 2679-2685. |
| [13] | 文永霞, 孙海, 陈小菊, 蔡婉静, 李淑妮, 郭洪花. 孕产妇分娩心理创伤评估工具的系统评价[J]. 中国全科医学, 2025, 28(20): 2555-2561. |
| [14] | 张冰清, 王忠凯, 吴长勇, 孙煌, 李锐洁, 刘文洁, 骆怡哗, 郑丽慧, 彭云珠. 1990—2021年全球先天性心脏缺陷疾病负担变化及未来趋势预测研究[J]. 中国全科医学, 2025, 28(18): 2253-2261. |
| [15] | 曹晨晨, 郑吕云, 王琳, 刘静. 高血压与2型糖尿病共病患者家庭医生签约服务偏好研究[J]. 中国全科医学, 2025, 28(16): 2011-2016. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||










