
Page 95 - 中国全科医学2022-01
P. 95
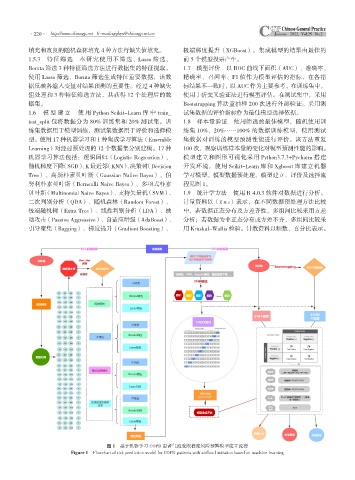
·220· http://www.chinagp.net E-mail:zgqkyx@chinagp.net.cn
填充和改良的随机森林填充 4 种方法行缺失值填充。 极端梯度提升(XGBoost)。集成模型的结果由最佳的
1.5.3 特征筛选 本研究使用不筛选、Lasso 筛选、 前 5 个模型投票产生。
Boruta 筛选 3 种特征筛选方法进行数据集的特征提取。 1.7 模型评价 以 ROC 曲线下面积(AUC)、准确率、
使用 Lasso 筛选、Boruta 筛选生成特征重要数据,该数 精确率、召回率、F1 值作为模型评估的指标,在各指
据反映各输入变量对结果预测的重要性。经过 4 种缺失 标结果不一致时,以 AUC 作为主要参考。在训练集中,
值处理和 3 种特征筛选方法,共获得 12 个处理后的数 使用十折交叉验证法进行模型评估。在测试集中,采用
据集。 Bootstrapping 算法重抽样 200 次进行外部验证。采用测
1.6 模 型 建 立 使 用 Python Scikit-Learn 库 中 train_ 试集数据的评价指标作为最佳模型选择依据。
test_split 包将数据分为 80% 训练集和 20% 测试集。训 1.8 样本量验证 使用筛选的最佳模型,随机使用训
练集数据用于模型训练,测试集数据用于评价和选择模 练集 10%、20%……100% 的数据训练模型,使用测试
型。使用 17 种机器学习和 1 种集成学习算法(Ensemble 集数据对训练的模型预测性能进行评价。该方法重复
Learning)对经过预处理的 12 个数据集分别建模。17 种 100 次,观察训练样本量的变化对模型预测性能的影响。
机器学习算法包括:逻辑回归(Logistic Regression)、 模型建立和图形可视化采用 Python3.7.3+Pycharm 搭建
随机梯度下降(SGD)、K最近邻(KNN)、决策树(Decision 开发环境,使用 Scikit-Learn 库和 Xgboost 库建立机器
Tree)、高斯朴素贝叶斯(Gaussian Naïve Bayes)、伯 学习模型。模型数据预处理、模型建立、评价及选择流
努利朴素贝叶斯(Bernoulli Naive Bayes)、多项式朴素 程见图 1。
贝叶斯(Multinomial Naive Bayes)、支持矢量机(SVM)、 1.9 统计学方法 使用 R 4.0.3 软件对数据进行分析。
二次判别分析(QDA)、随机森林(Random Forest)、 计量资料以( ±s)表示,在不同数据预处理方法比较
极端随机树(Extra Tree)、线性判别分析(LDA)、被 中,若数据正态分布及方差齐性,多组间比较采用方差
动攻击(Passive Aggressive)、自适应增强(AdaBoost)、 分析;若数据为非正态分布或方差不齐,多组间比较采
引导聚集(Bagging)、梯度提升(Gradient Boosting)、 用 Kruskal-Wallis 检验。计数资料以频数、百分比表示。
图 1 基于机器学习 COPD 患者气流受限程度风险预警模型建立流程
Figure 1 Flowchart of risk prediction model for COPD patients with airflow limitation based on machine learning